
このコラムでは、今回の「2025年東京都議選をめぐる有権者の政治意識調査」の調査方法と、回答者集団についての詳しい情報を説明します。
今回、アンケートに答えてくれたのは、アイブリッジ株式会社が保有する登録者パネルの中で、東京都に在住されている方です。この人々を調査対象にして、東京都の有権者集団の傾向がなぜ導き出せるのだろうか?そのように思った方はいないでしょうか。
調べたい集団(母集団と呼びます)の一般的な傾向を、一部の調査対象の結果から推測するには、調査対象者(サンプルと呼びます)を選び出す方法が鍵を握っています。
このことを、味噌汁の例で説明してみたいと思います。
統計調査は、「味噌汁の味見」?
みなさんは味噌汁の味を確かめる時、調理途中の味噌汁を全部飲み干して、味を確かめることはしませんよね。よくかき混ぜて、一口すくって味を確かめると思います。この「味噌汁全部」が母集団、「味見の一口」が「サンプル」にあたります。
この「一口」は、味を確かめる上で妥当な「一口」でなくてはいけません。味見の際には、味噌が底に沈殿している状態で、上澄を掬ってしまわないようにしますよね。「一口」が鍋全体の味を確認できるものにするためには、しっかり味噌汁全体を混ぜることが重要です。
社会調査でも、サンプルを選ぶ時には、母集団の代表を抽出する工夫が必要です。さまざまな属性や考えを持った多様な人たちをぐちゃぐちゃに並び替え、そしてそこから「まんべんなく」選び、その人たちへ調査できれば、母集団の傾向を確からしい形で知ることができるようになります。こうした選び方のことを、ランダムサンプリング(無作為抽出)と呼びます。
今回の調査では、調査会社の保有パネルの方に調査をしています。そのため厳密には、東京都の有権者全体から満遍なく対象者を選び出すランダムサンプリングではありません。
しかし、予めわかっている母集団の情報を頼りにすることで、似たような形で調査対象者を選び出すことは可能です。また、実際に回答が集まった後、サンプルが母集団からずれていないかを事後的に確認することもできます。例えば行政が公表しているデータ等と比較して、サンプルのズレを調整する。そのことで、サンプルの「一口の妥当性」が確認できます。
東京都の人口構成にあわせた“声”の集め方
今回のサンプルはどういうものか
では今回の調査の調査対象者の選び方と、母集団である東京都民全体との構成比較を行った結果を次に説明していきたいと思います。
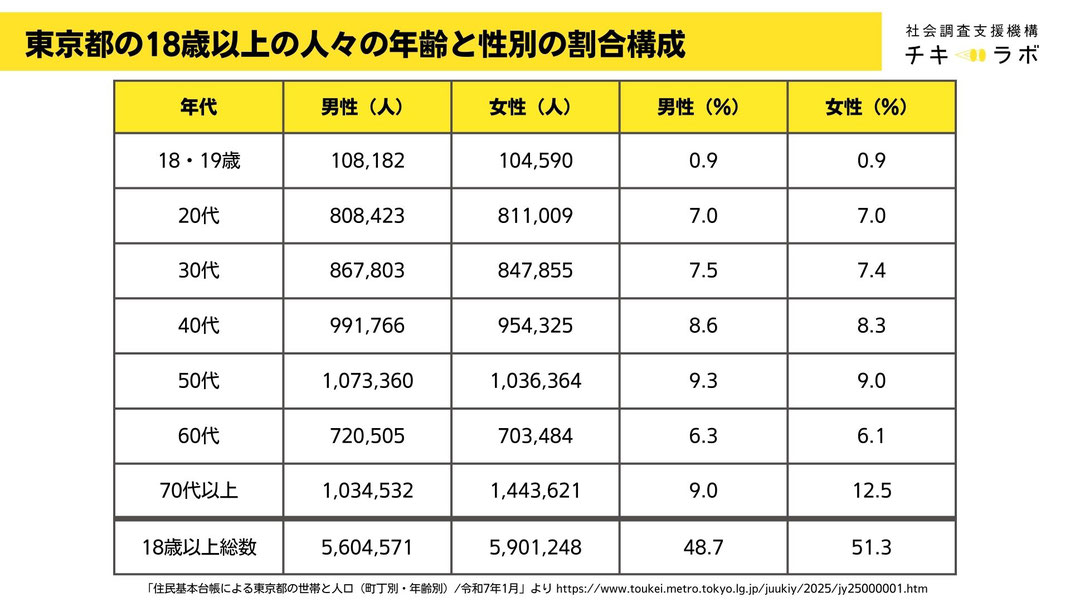
今回、アンケートに答えてくれたのは、アイブリッジ株式会社が保有する登録者パネルの中で、東京都に在住されている方です。さらに、回答者の年齢と性別の割合が、調査対象となる東京都の18歳以上の人々の年齢と性別の割合に合うように、年代ごと、性別ごとに回収数をあらかじめ設定して実施するという「割付」という手続きをおこないました。
東京都の18歳以上の年齢と性別の構成割合はこちらのデータを参照し、調べました。
「住民基本台帳による東京都の世帯と人口(町丁別・年齢別)/令和7年1月」https://www.toukei.metro.tokyo.lg.jp/juukiy/2025/jy25000001.htm
このデータから、東京都の18歳以上の人々の年齢と性別の割合構成は以下のように計算することができました。右側の比率の数字は、18歳以上の総数(男女合計数)に対する割合です。
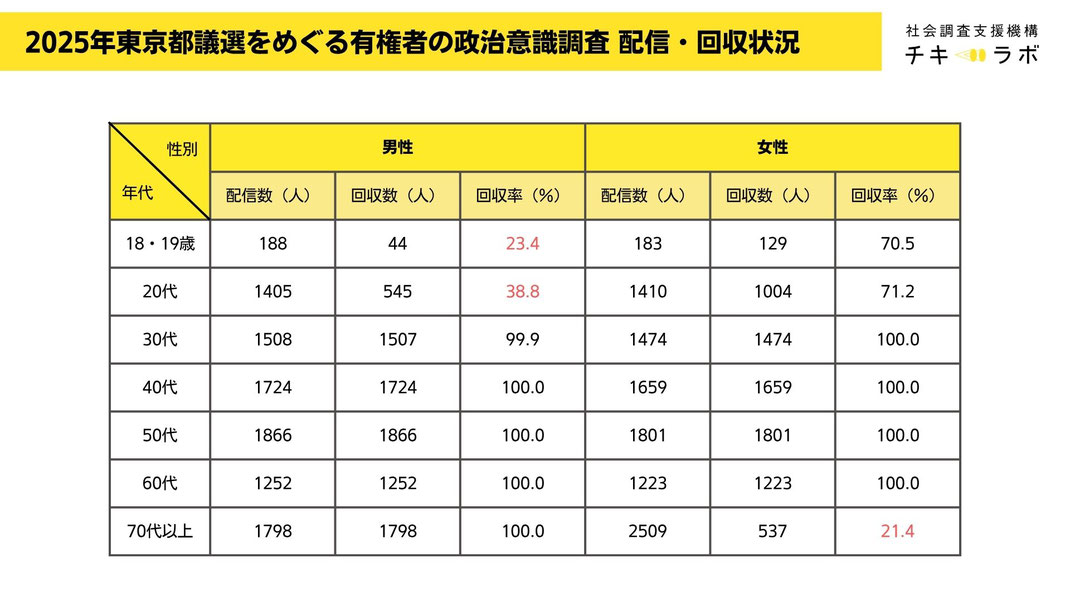
そして、この上の表の右側の比率をもとにアンケートの配信数を次のように設定しました。当初、全部で20,000人分の回答を得ることを目標としたため、上の表の性別・年代の比率に20,000をかけた結果、次の表のような人数(以下の表「配信数」にある人数)で各性別・年代の方々にアンケートを配信しました。そして実際に回収できた数は下の表「回収数」にある通りです。
社会調査につきものの“サンプルの偏り”
ご覧いただくとわかる通り、18・19歳・20代の男性、そして70代以上の女性が少ないサンプルになっているのが今回の2025年東京都議選をめぐる有権者の政治意識調査で得られたデータ(以下、都議選データ)です。
母集団(調査したい集団)ーここでは東京都の18歳以上の人々ーとサンプルに差があることを「サンプルバイアス」と呼びますが、一般的に社会調査では、サンプルを母集団から満遍なく選ぶこと(ランダムサンプリング/無作為抽出)を完全に実現することはできませんので、こうしたサンプルバイアスはかならず生じます。
サンプルを母集団の構成に近づけるためには、少なくなってしまっている18・19歳・20代の男性の回答傾向を「重みづけ」するという方法もあります。例えば18・19歳・20代の男性から100人の回答を集めたかったが、25人の回答しか得られなかった場合には、1人の回答を4人分相当の回答として扱うことで、結果的に100人分に相当するように調整します。そうすることでこの層の意見が全体において適切な比率で反映されるようにするのが、「重みづけ」です。
しかし、回答者数が少ない層に重みをかけると、その中に特異な回答があった場合に、その影響が全体の結果に強く表れてしまうという問題もあります。
今回は、男性や高齢女性の政治意識に注目する場合には、特にこのサンプルバイアスがある点をおさえ、慎重に解釈しています。また、この層がテーマとなっていない場合でも、若年男性・高齢女性の回答が反映されにくいデータである点をおさえながら分析結果を読み解いています。
世帯年収の分布は妥当か?東京都のデータと比較
サンプルの世帯年収構成についても東京都の傾向と比べておきましょう。
東京都の世帯年収の分布は東京都がWebで公表しているデータから入手することが困難でしたので、代わりに令和6年1月にまとめられていた『都民生活に関する世論調査』(https://www.metro.tokyo.lg.jp/documents/d/tosei/01_02_156)
で得られているデータを参照しました。
こちらのデータは、都議選データと同じく、東京都の18歳以上の人々を対象としており、層化二段無作為抽出法という方法で、サンプルを得ています。アンケートは郵送で送り、回答は紙に、またはオンラインでも可能な設計となっているようです。こちらは44.6%の有効回答数となっています。調査対象とした人たちのうち、約4割の人たちがアンケートに回答してくれた、ということです。詳しい調査方法は調査報告書をご覧ください。
そのデータと都議選データで得た世帯年収の分布を比べた結果が以下の表です。
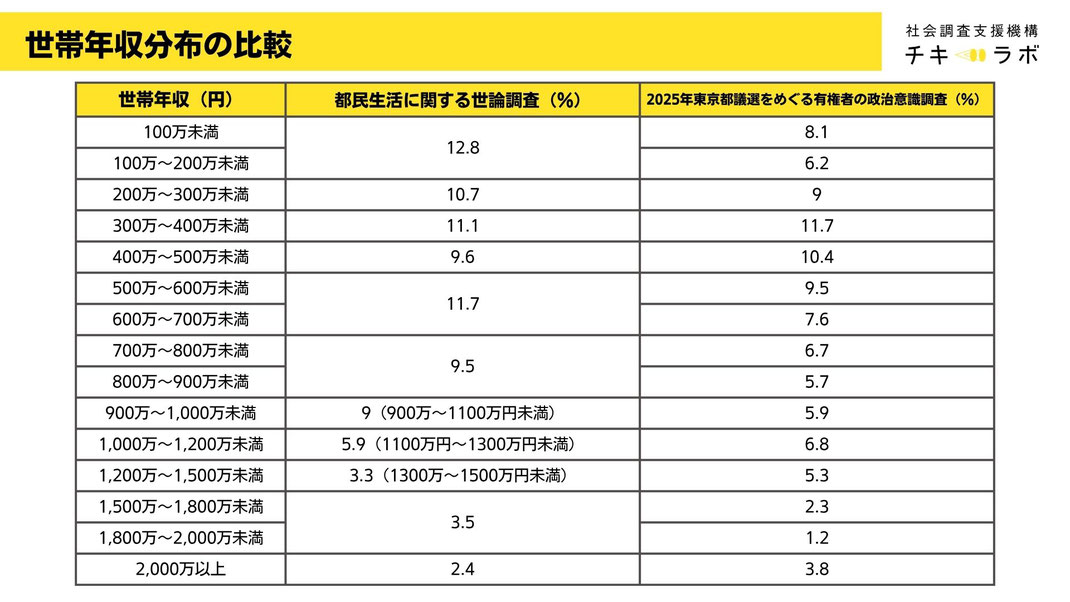
一部、収入帯の設定が違っているので比べにくくなっているところもありますが、概ね、同水準の数値が得られています。
また2本目の記事「参政党に投票したのは、どんな人なのか 〜参政党への投票行動を分析する②」
の中で紹介した、都知事選の投票先の割合、各候補の順位を実際の結果と比べても、都議選データのサンプルは概ね妥当な構成となっていることが確認できます。
大量のお味噌汁を味見するには?――社会調査とサンプルの話
なぜ400人程度のサンプルで、1100万人もの人間の動向を把握することができるのかは、冒頭の味噌汁の話を思い出してください。味噌汁全体が母集団、味見のためにすくった量がサンプルです。
一定以上の量をすくえば、味見は可能です。今回の調査でも、東京都の有権者の動向を把握できる「味見に必要な量」を確保することになります。今回はスクリーニング調査では合計16390人、そこから本調査を送り、確保した回答数は合計418人分でした。
同時に、参政党に投票した人の数は、参政党候補者が出馬していた4地区の合計で117,389票。この動向を分析するためにも、やはり380人程度が必要になります。
1100万人の傾向を把握するためのサンプル数と、12万人の傾向を把握するための必要サンプル数がそれほど離れていないことは、不思議に感じられるかもしれません。細かな説明は省略しますが、家庭用味噌汁の味見も、給食用の寸胴で作った味噌汁の味見も、「味見の一口」の量が一気に変わるわけではないのと似ています。
「お味噌汁を大量に作った場合、お椀いっぱいを飲まなくて、味見にはならない」ということにはならないですよね。重要なのは、「ちゃんとかき混ぜた」と言える状態に近づけること、あるいは「どんな偏りのある一口」なのか理解することです。
都議選で参政党に投票した人は、全体の有権者のうちでは1%程度。1万人に聞いても100人程度しかいないことになります。今回の調査では、2万人にスクリーニング調査を行ったので、200人程度の参政党投票者からの回答を確保することを目指しました。それでようやく、信頼区間が85-90%程度となります。最終的に今回の調査では、参政党に投票したサンプル数が241となりました。
今回の量的調査では、こうした工夫を重ねながら、なるべく妥当なサンプルになるよう心がけています。同時に、その調査限界を把握しながら、注意深く分析しています。その上で、
「調査の範囲から言えること」に絞って、データの発信を続けています。
チキラボの活動はみなさまのご寄付に支えられております。
調査・研究の成果は記者会見やメディアを通じて発信していくほか、
チキラボウェブサイトの調査・研究成果のページでも公開して参ります。
月額1,000円からご支援いただけます。
マンスリーサポーター限定イベント、Facebookグループへのご招待の特典もございまので、是非ご登録ください。
ご自身で寄付金額をお選びいただけます。